Mejorando la Performance en Shiny con Pins
September 28, 2020TL;DR Si tenes tenes una aplicación en Shiny que tarda mucho en cargar debido a un proceso de la data que es intensivo en tiempo, y no es importante que el resultado se calcule en real time, entonces seguramente tengas que empezar a usar la librería pins.
Esta es la historia de cómo logré reducir el tiempo de carga de mi aplicación de 44 a 4 segundos, aunque lastimosamente no puedo mostrarla por cuestiones de privacidad… motivo por el cual tedrán que confiar en mi palabra y saber que quien llegue hasta el final tendrá su recompensa. 🐱
El problema
Desde hace un tiempo que la aplicación en cuestión viene realizando un proceso muy intensivo, el cual lee varias bases de datos y realizar cálculos históricos muy grandes, y por suerte también viene creciendo el uso… lo cuual implica que he empezado a trabajar mucho más fuertemente con paquetes como profvis y shinyloadtest para detectar dónde están los cuellos de botella en el procesamiento.
Sobre el punto anterior voy a mencionar que, si bien siempre existirán oportunidades de mejora al código para hacerlo más rápido, no nos importa en este momento y pido, nuvamente, que confíen cuando les digo que los intentos por optimizar estuvieron presentes.
Hay que tener en cuenta estoy usando la versión Open Source de Shiny la cual maneja la concurrencia sobre un único hilo (single thread), lo cual impacta de lleno en el usuario final. Si tenemos múltiples usuarios conectados realizando una acción que sea intensiva en tiempo de cálculo, todos sentirán que pasan años hasta ver el resultado final… Por suerte esta situación es posible de superar (o mejorar) utilizando programación asincrónica mediante las librerías promises y future… aunque este no será el tema del post…
El resumen de la situación es el siguiente: existe un proceso que tarda mucho y no se va a poder mejorar el tiempo optimizando el código.
Otra cosa aún más importante: No me interesa guardar el resultado de estos cálculos! Con esto dejo en claro que no me interesa guardar en la DB el resultado, ni aunque sea un parcial.
La estrategia
Habiendo dejado en claro que no es importante procesar la data en tiempo real al momento de ingresar a la aplicación, se presenta la oportunidad de realizar el cálculo en algún otro lado, por ejemplo, exponiendo al proceso en una API mediante plumber corriendo en Cloud Run usando Cloud Scheduler.
Desde ya que puedo armar un post más adelante parar mostrar cómo hacer lo anterior… y seguramente lo haga!
Habiendo resuelto el “dónde se correrá el proceso”, y sabiendo que la frecuencia de cálculo es simplemente un parámetro que eligiremos según la necesidad, entonces nos resta saber “dónde se disponibilizará el dataset resultante”.
La solución: pins
Esta librería, bastante nueva, sirve para guardar elementos que tenemos localmente en ‘buckets’ (cubetas… (?)) en la nube y poder compartirlos de forma bastante sencilla.
En mi caso, mi cubeta o bucket, estará alojada en Google Cloud Storage, así que daré por hecho que quien este deseando seguir este mini tutorial ya tendrá una cuenta en Google Cloud.
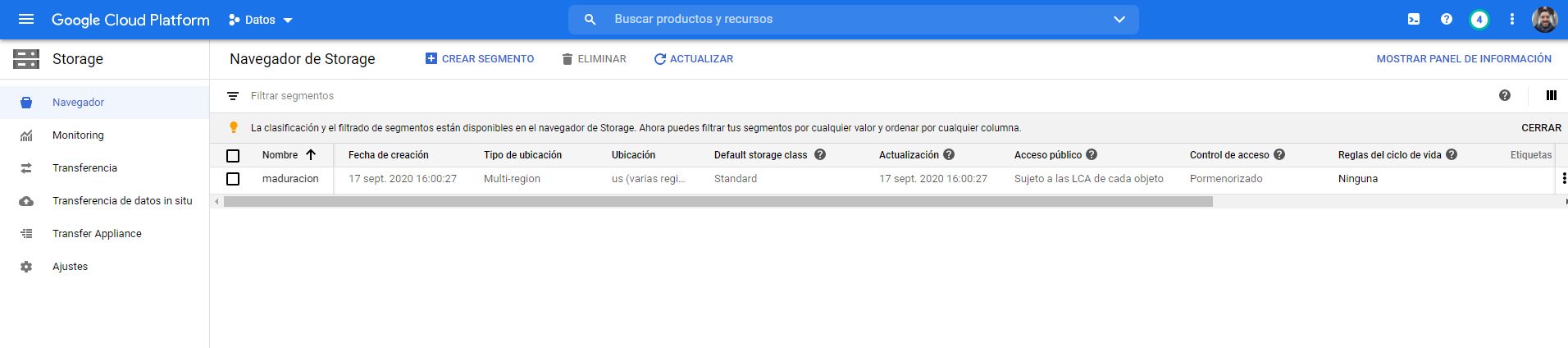
El proceso será el siguiente:
- Vamos a crear un bukcet en GCS (Google Cloud Storage de ahora en más). Es importante crearlo manualmente antes de querer llamarlo desde la librería, la misma no crea automáticamente el bucket
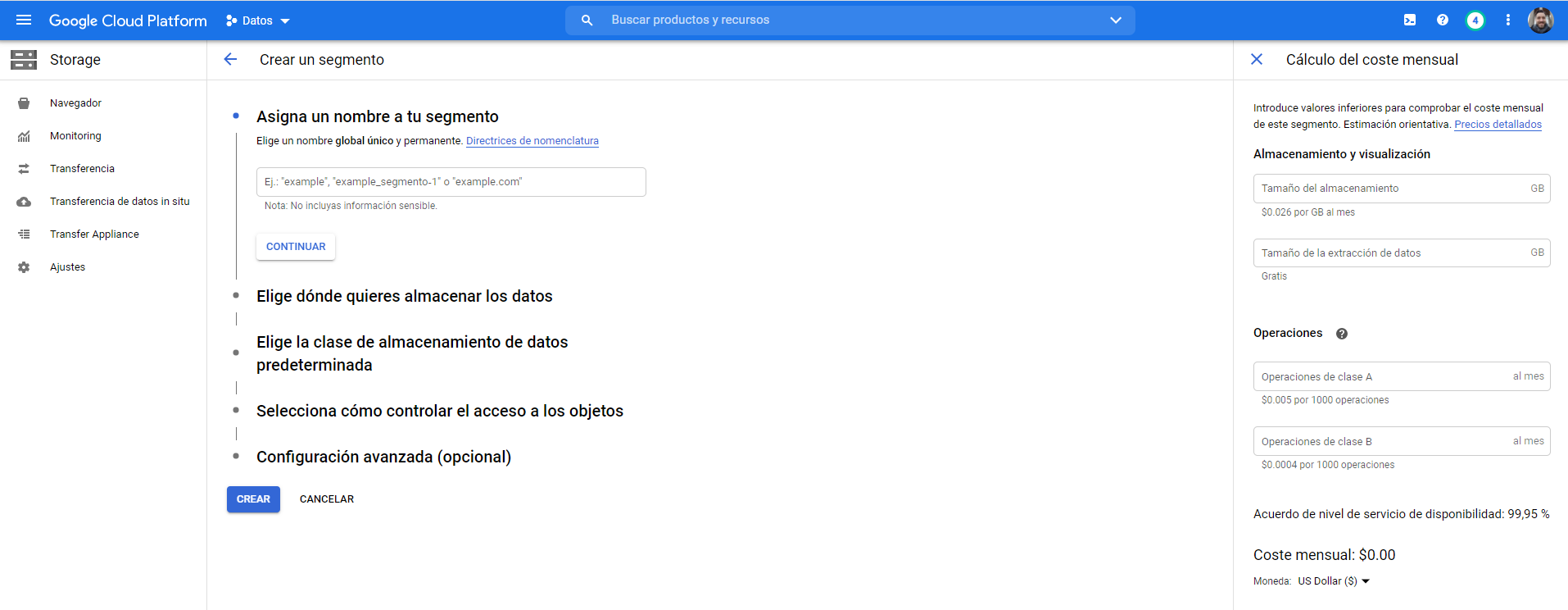
- Vamos a crear una cuenta de Servicio, la cual será utilizada para acceder a la información.
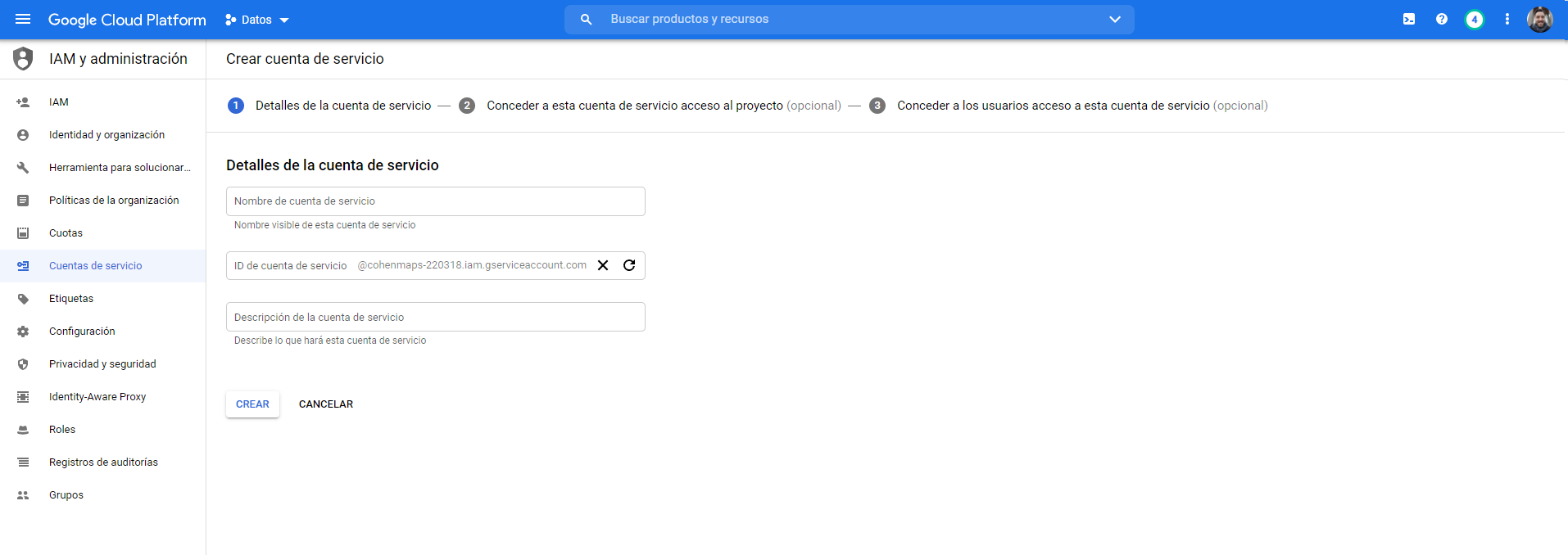
- VAmos a ingresar a IAM y daremos permisos de Administrador de Storage y Administrador de Objetos de Storage. La decisión de cuántos permisos asignar al usuario de servicio va a depender de ustedes.
- Y listo!
Mmm… no.. 😡 aún falta una parte y es la autenticación con OAuth 2.0 para usar la API de GCS con pins, pero estp lo dejaremos para el final porque he sufrido varios dolores de cabeza hasta lograrlo…
Suponiendo que ya he logrado autenticarme entonces hay 3 funciones para aprenderse de la librería pins:
pins::board_register_gcloud(): la cual sirve para registrar una conexión a nuestro bucket. Lo importante es que tengo que pasar un token que obtengo mediante la autenticación con OAuth 2.0, ya lo veremos al final…pins::pin(): función mediante la cual podremos subir nuestro set de datos al bucket.pins::pin_get(): con la cual podremos obtener el set de datos deseado que está en nuestro bucket.
Hay que tener presente que cada vez que escribamos en nuestro bucket con pins::pin() estaremos pisando el dataset que se llame igual al que estemos pasando en la función, por lo cual, esto es muy útil cuando nos interesa únicamente el último resultado del proceso.
Esta estrategia puede ser muy útil si se la cambina con plumber, por ejemplo, para exponer el resultado de modelos directamente a las llamadas de las APIs, en vez de calcularlo en el momento. O, por ejemplo, para compartir información entre procesos utilizando shiny.
No esta de más decir que haber hecho esto representó una gran mejora a nivel usabilidad en mi aplicación, motivo por el cual se los recomiendo probar.
Si bien yo utilizo el entorno de GCS, con pins también se puede uno conectar a otras opciones tales como: Kaggle, GitHub, DigitalOcean, S3, Azure, etc.
Otras opción para conectarse a GCS: googleCloudStorageR
Para conectarse a GCS existe otra librería creada por Mark Edmondson llamada googleCloudStorageR.
📢 Les super recomiendo seguir a Mark, ya que suele escribir bastante sobre el uso de R en la nube (de Google en particular) y además ha creado muchas librerías que sirven para conectarse a las APIs de Google.
OAuth 2.0
Ahora les voy a contar cómo resolví la autenticación con la API de GCS.
En resumen: en Google Cloud vamos a obtener un json que tiene la configuración necesaria para lograr, mediante gargle::credentials_service_account(), obtener el token que necesitamos para conectarnos a nuestro bucket. Lo que hay que saber es que este token vence, motivo por el cual, tenemos que ajustar nuestro código ante esta situación.
Manos a la obra:
- Obtengo el json desde cuentas de servicios, haciendo click en “Añadir Clave”.

Voy a guardar el json en algún lugar seguro. En mi caso, lo guardo en un repositorio en GitHub al cual acceso mediante la API de GitHub con mi Access Token personal.
Voy a obtener el token utilizando la función
gargle::credentials_service_account()y lo voy a guardar en mi DB.Cada vez que alguien ingrese a mi aplicación y pida conectarse al bucket voy a chequear que el token aún sea valido y, si no lo es, lo volveré a obtener.
Para esto último, armé la siguiente función que dejo a disposición y a la cual deberán modificar según su propio proceso:
google_service_credentials <- function(connection, url) {
# Leo las credenciales actuales
credentials <- dbGetQuery(conn = connection, "SELECT Servicio, UserName, Url, Token, ModificationDateTime FROM Credenciales WHERE Servicio IN ('GCS', 'GitHub');")
credentials_github <- credentials %>% filter(Servicio == 'GitHub')
credentials_gcs <- credentials %>% filter(Servicio == 'GCS')
# Obtengo tiempo desde la última actualización
diff <- lubridate::interval(
lubridate::as_datetime(credentials_gcs$ModificationDateTime, tz = "America/Argentina/Buenos_Aires"),
lubridate::now()
) %>%
lubridate::time_length(unit = "minutes")
# Refresco el token de ser necesario
if (diff > 60) {
cred <- gargle::credentials_service_account(
scopes = credentials_gcs$Url,
path = GET(url = url,
authenticate(credentials_github$UserName, credentials_github$Token),
accept(type = "application/vnd.github.v3.raw")) %>%
content(as = "text")
)
sql <- str_c("UPDATE Credenciales SET Token='", cred$credentials$access_token, "', ModificationDateTime=CURRENT_TIMESTAMP WHERE Servicio = 'GCS';")
dbExecute(connection, sql)
token <- cred$credentials$access_token
} else {
token <- credentials_gcs$Token
}
return(token)
}Ahora si, ¡hemos logrado conectarnos a nuestro bucket! 🚀
Solamente resta usar la función anterior para actualizar automáticamente el token de la siguiente manera: pins::board_register_gcloud(bucket, token = google_service_credentials(connection, url)).
Y… llegar al final tiene su recompensa: un gato-abeja!

PD: por si alguien aún no conoce, les dejo el podcast de Shiny Developers Series en donde vienen realizando muy buenas entrevistas a los referentes de la comunidad de Shiny. Básicamente están todos los autores de las librerías que usamos diariamente: https://shinydevseries.com/
![]()