Exponiendo Funciones de R en la Nube: Parte 1
March 9, 2020TL;DR: El resultado final de este trabajo lo pueden encontrar en el siguiente link https://demo-api.hasselpunk.com/ 😁
Este será el primer posteo de una serie de 3, los cuales tendrán dos intenciones: mostrar como exponer funciones de R en la nube y dejar por escrito ciertas recomendaciones que surgieron en el proceso de desarrollo. Estoy seguro que estos consejos servirán a más de uno (incluso a mi ‘yo’ del futuro!!!).
La serie constará de los siguientes posteos:
- En el primero vamos a explicar cómo usar PlumbeR para exponer funciones de R y crear un informe (tanto en HTML como en PDF!).
- En el segundo vamos a correr nuestra API con Docker localmente. Vamos a aprender a crear el dockerfile necesario para esto.
- Por último veremos cómo vincular GitHub con Cloud Run (de Google Cloud) usando Cloud Build para exponer nuesta API en la nube!
La motivación
Siempre surge la charla de cómo llevar R a producción y, estoy seguro que con ciertas herramientas que surgieron en los últimos años, hoy es mucho más sencillo de hacerlo de lo que muchos piensan. La intención no es desarrollar una aplicación con Shiny, sino concentrarnos en usar el protocólo REST para que nuestros super algoritmos puedan interactuar con otras aplicaciones y lenguajes.
Por otro lado, específicamente en este posteo, presentaremos una manera fácil de desarrollar informes que se puedan actualizar diariamente sin la necesidad de tener que generarlos localmente para luego enviarlos por mail. 😉
Supuestos y definiciones
- Quien desee seguir de punta a punta esta guía, deberá tener una cuenta en Google Cloud. Ya tendremos tiempo de ver los costos en otros posteos.
- Doy por sentado que quien lee esta guía entiende qué es una API REST y ha tenido alguna experiencia mínima con este protocolo.
- No soy un DevOps, así que cualquier oportunidad de mejora que vean, pueden agregarlas en los comentarios!
Manos a la obra!
¿Qué es PlumbeR? PlumbeR es un paquete de R que convierte el código que escribimos en R en una API REST. Esto lo logra gracias a ciertos comentarios que se agregan en el código, parecidos a Roxygen. Éste último sirve para documentar funciones en R y quienes hayan desarrollado alguna librería en el pasado estarán familiarizados.
Con las últimas versiones de RStudio, se puede crear una API con PlumbeR directamente desde el menú! Tan sencillo como ir a “File > Plumber API…” y luego hacer click en “Run API”:
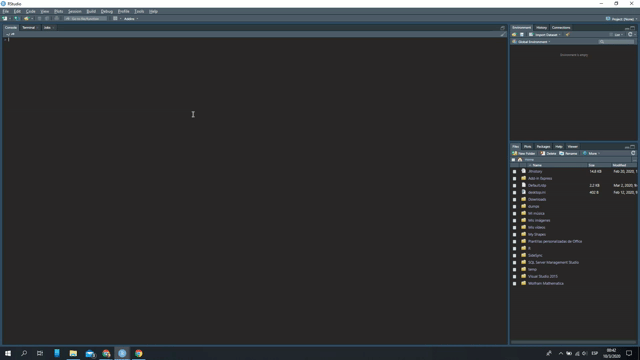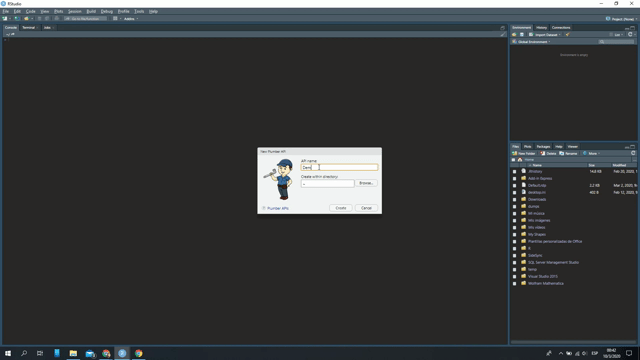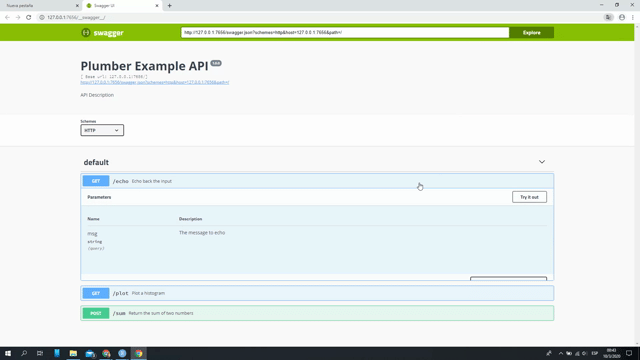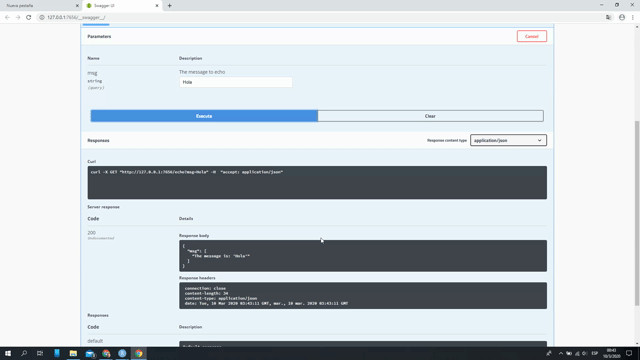
Ya con nuestra API demo funcionando, tenemos que entender que todo lo que estamos exponiendo, es una función y para ellos debemos de tener presente ciertas cuestiones propias de PlumbeR:
- La primer línea comentada denota el nombre de la función. Una vez que corramos nuestra API, veremos como se genera automáticamente documentación con Swagger.
- Luego veremos una línea que denota el tipo de método, puede ser un GET, POST, PUT, etc… Los princiales a tener en mente son los GET y POST, y la diferencia principal es que el primero representa métodos de lectura y el segundo un método de creación. Para ver en más detalle las diferencias entre los métodos les recomiendo este link: métodos HTTP
- Por último, encontrar los parámetros a pasarse en la función y estos los represetamos con
@param parametro:tipo.
Nuestra primer función!
#* Devuelve la suma de dos numeros
#* @get /sum
#' @param a:numeric El primer numero
#' @param b:numeric El segundo numero
function(a, b) {
as.numeric(a) + as.numeric(b)
}Es tan solo una suma, pero representa la base de cualquier cosa que deseemos realizar. Aquí lo importante es recordar que no es necesario que la función contenga todo la lógica, sino que nos podemos apoyar en crear otros archivos .R y ‘sourcearlos’. Para esto, tenemos que agregar source() al inicio, luego de cargar las librerías. Es importante no hacerlo dentro de la función, porque sino estaremos cargando el archivo cada vez que una persona haga un request a la función en cuestión, algo que no será para nada performante!
Qué saldrá de sumar 1.3 y 2? Veámosolo! https://demo-api.hasselpunk.com/sum?a=1.3&b=2
Un informe con parámetros y elementos dinámicos…
Si todos los días nos piden que armemos un informe y el mismo se puede parametrizar, entonces esto les va a encantar: podemos armar un archivo .Rmd y luego exponerlo como una función!
#* Informe en HTML
#* @get /html
#' @serializer contentType list(type="application/html; charset=utf-8")
#' @param stock:character Ticker obtenido desde Yahoo Finance
function(res, stock="BTC-USD"){
f <- rmarkdown::render("InformeHTML.Rmd",
output_format = NULL,
params = list(stock = stock))
include_html(f, res)
}Aquí hay algo curioso a tener en cuenta: utilizar la función nativa plumber::include_rmd() para renderizar el .Rmd no tendrá mucho sentido, ya que la misma no pasa los argumentos de los parámetros que podamos usar con Rmd…. pero aquí viene un gran consejo de Hadley Wickham: usar F2. Esto es: hacer click en la función y luego en F2 para ver su código fuente! De esta manera veremos cómo está implementado, y a lo sumo podremos hacer los cambios necesarios según nuestra conveniencia.
Vemos que no hay mucha diferencia entre la función de plumber y mi función, ambas usan include_html(), pero mi código pasa los parámetros dentro de render():
function (file, res, format = NULL)
{
requireRmd("include_rmd")
f <- rmarkdown::render(file, format, quiet = TRUE)
include_html(f, res)
}El resultado es un método al cual se le puede pasar el nombre del ticker (sigla que tienen los instrumentos financieros y los pueden buscar en yahoo finance) y generará un sitio con un informe en HTML. Veamos cóm ha evolucionado la cotización de la Bolsa de Buenos Aires o de Tesla.
Pueden probar buscar ustedes mismos otros productos financieros y armar sus informes respetando la siguiente estructura https://demo-api.hasselpunk.com/html?stock=TSLA
Un informe con parámetros en PDF
Quizás un informe con elementos dinámicos no sea la mejor opción para quienes desean imprimirlo, es por esto que también creamos un informe pero en PDF:
#* Informe en PDF
#* @get /pdf
#' @serializer contentType list(type="application/pdf; charset=utf-8")
#' @param stock:character Ticker obtenido desde Yahoo Finance
function(res, stock="BTC-USD"){
temp <- tempfile(fileext = ".pdf")
rmarkdown::render("InformePDF.Rmd",
output_file = temp,
output_format = NULL,
params = list(stock = stock))
readBin(temp,'raw', n = file.info(temp)$size)
}Esta secuencia me ha llevado un tiempo pero finalmente logré darme cuenta que:
- Hay que generar un archivo temporal con extensión
.pdf - Luego debemos guardar el pdf renderizado en el archivo temporal que hemos creado
- Finalmente leeremos este archivo temporal.
Con estos pasos lograremos generar un PDF que se podrá ver en el navegador. Veamos como fue la evolución del Bitcoin en los últimos 6 meses: https://demo-api.hasselpunk.com/pdf?stock=BTC-USD
Es muy importante usar
@serializerpara mostrar cual es el tipo de contenido con el que estamos trabajando.
Lo logramos!
Con esto ya hemos logrado automatizar parte de nuestro trabajo: ahora los informes se generan mediante parámetros consultando a una API y nuestros super algorítmos ya están expuestos también para que otros lo usen. 🔥
Pueden jugar con la API Demo que tengo en la nube y ver qué métodos están disponibles en https://demo-api.hasselpunk.com/
En siguientes posteos seguiremos trabajando para lograr llevar todo esto a la nube! ☁️
![]()